6мқј н•ңкөӯм „мһҗнҶөмӢ м—°кө¬мӣҗ(ETRI)м—җ л”°лҘҙл©ҙ мң„нӮӨл°ұкіјмҷҖ лІ•л № л“ұ л¬ём–ҙмІҙлҘј мЈјлЎң мқҙн•ҙн•ҳлҠ” м–ём–ҙ분м„қ AI 'м—‘мҶҢлёҢл Ҳмқё'мқ„ нҷ•мһҘ, кө¬м–ҙмІҙ 분м„қмқҙ лҗҳлҸ„лЎқ кі лҸ„нҷ”н–ҲлӢӨ. лҢҖнҷ” 분м„қмҳӨлҘҳлҘј мөңлҢҖ 41% к°ңм„ н–ҲлӢӨ.
кё°мЎҙ кё°мҲ мқҖ '충мІӯлҸ„мқёлҚ°'лҘј '충мІӯлҸҲлҚ°'лқјкі н‘ңнҳ„н•ҳлҠ” кІҪмҡ° '충мІӯлҸ„+мқёлҚ°'лқјлҠ” 축м•Ҫ н‘ңнҳ„мқ„ мқёмӢқн•ҳм§Җ лӘ»н•ң мұ„ '충мІӯлҸҲ+лҚ°'лқјкі 분м„қн•ҳлҠ” н•ңкі„к°Җ мһҲм—ҲлӢӨ.
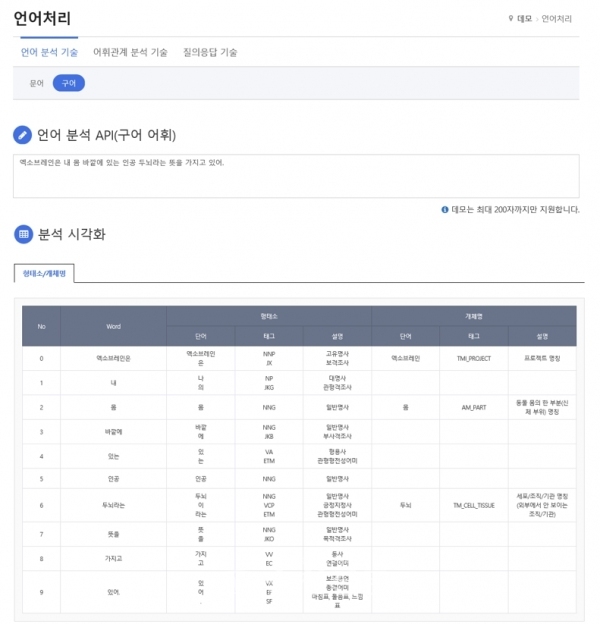
ETRIк°Җ кіөк°ңн•ң кө¬м–ҙмІҙ м–ём–ҙ분м„қ кё°мҲ мқҖ нҒ¬кІҢ нҳ•нғңмҶҢ분м„қ кё°мҲ кіј к°ңмІҙлӘ… мқёмӢқ кё°мҲ л‘җк°Җм§ҖлӢӨ. нҳ•нғңмҶҢ분м„қ кё°мҲ мқҖ н•ңкөӯм–ҙ мқҳлҜё мөңмҶҢ лӢЁмң„лҘј 분м„қн•ҳлҠ” кё°мҲ мқҙкі , к°ңлӘ…мІҙ мқёмӢқ кё°мҲ мқҖ л¬ёмһҘ лӮҙ кі мң лҢҖмғҒкіј к·ё мқҳлҜёлҘј мқёмӢқн•ңлӢӨ. 'көӯлҜјмқҖн–ү'мқҙ 'көӯлҜј'кіј 'мқҖн–ү'мқҙлқјлҠ” лӘ…мӮ¬мқҳ кІ°н•©мқҙ м•„лӢҢ кі мң лӘ…м№ӯмқҙлқјлҠ” м җмқ„ мқёмӢқн•ҳлҠ” кё°мҲ мқҙлӢӨ.
м—°кө¬м§„мқҖ н•ҷмҠө лҚ°мқҙн„° л¶ҖмЎұ н•ңкі„лҘј к·№ліөн•ҳкё° мң„н•ҙ мқҙлҜё мЎҙмһ¬н•ҳлҠ” нғҖ 분야мқҳ н•ҷмҠө лӘЁлҚёкіј мҶҢлҹүмқҳ н•ҷмҠөлҚ°мқҙн„°лҘј мһ¬мӮ¬мҡ©н•ҳлҠ” л°©мӢқмқ„ мқҙмҡ©н–ҲлӢӨ.
кІ°кіјлЎң, кё°мЎҙ лӘЁлҚё лҢҖ비 нҳ•нғңмҶҢ분м„қкіј к°ңмІҙлӘ… мқёмӢқ м„ұлҠҘмқҙ к°Ғк°Ғ 5%, 7.6% к°ңм„ лҗҗмңјл©° мҳӨлҘҳлҠ” 41.74%, 39.38% к°җмҶҢн–ҲлӢӨ. нҠ№нһҲ, нҳ•нғңмҶҢ분м„қмқҖ мӮ°м—…кі„м—җм„ң мӮ¬мҡ©лҗҳлҠ” н•ңкөӯм–ҙ нҳ•нғңмҶҢ분м„қ мҳӨн”ҲмҶҢмҠӨ мӨ‘ н•ҳлӮҳмқё л©”мәЎ(Mecab) мҳӨн”ҲмҶҢмҠӨ лқјмқҙлёҢлҹ¬лҰ¬ лҢҖ비 10.6% лҚ” мҡ°мҲҳн•ң кІғмңјлЎң нҸүк°ҖлҗҗлӢӨ.
н•ҙлӢ№ кё°мҲ мқҖ 'кіөкіө AI мҳӨн”Ҳ APIВ·лҚ°мқҙн„° м„ң비мҠӨнҸ¬н„ё'м—җм„ң м„ ліҙмқҙкі мһҲлӢӨ.