27мқј KAISTм—җ л”°лҘҙл©ҙ м „мӮ°н•ҷл¶Җ мқҙмһ¬кёё көҗмҲҳ м—°кө¬нҢҖмқҙ мқҙк°ҷмқҖ 'л№„м„ нҳё(жҜ”йҒёеҘҪ) нҠ№м„ұ м–өм ң' кё°мҲ мқ„ кі м•Ҳн•ҙ нӣҲл Ё лҚ°мқҙн„° л¶ҖмЎұм—җ лҢҖн•ң н•ҙкІ° л°©м•Ҳмқ„ м ңмӢңн–ҲлӢӨ.
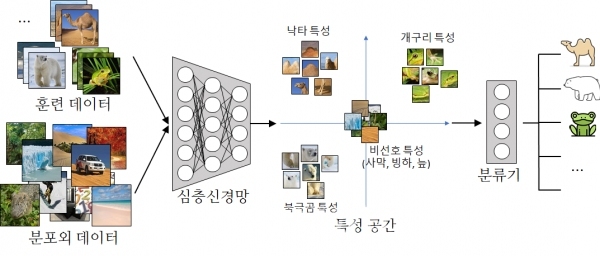
мқёкіөм§ҖлҠҘмқҙ лӮҷнғҖлҘј кө¬л¶„н•ҳлҸ„лЎқ л”Ҙлҹ¬лӢқ нӣҲл Ёмқ„ н•ҳлҠ” кІҪмҡ°, 'лӮҷнғҖ'лқјкі лӢөмқ„ м ҒмқҖ м—¬лҹ¬ лӮҷнғҖмӮ¬м§„мқ„ нӣҲл Ё лҚ°мқҙн„°лЎң м ңкіөн•ҳл©ҙ мқёкіөм§ҖлҠҘмқҖ лӮҷнғҖмқҳ мЈјмҡ” нҠ№м„ұмқҙ л“ұм—җ мһҲлҠ” нҳ№мқҙлқјлҠ” кІғмқ„ м•Ңм•„лӮҙкі лӮҷнғҖлҘј к°Җл ӨлӮёлӢӨ.
н•ҳм§Җл§Ң нӣҲл Ё лҚ°мқҙн„°к°Җ 충분н•ҳм§Җ м•Ҡмңјл©ҙ м Ғн•©н•ҳм§Җ м•ҠмқҖ нҠ№м„ұк№Ңм§ҖлҸ„ к°ҷмқҙ 추м¶ңлҗҳлҠ” л¬ём ңк°Җ л°ңмғқн•ңлӢӨ. лӮҷнғҖ л°°кІҪмңјлЎң мў…мў… л“ұмһҘн•ң мӮ¬л§үмқ„ лӮҷнғҖ нҠ№м„ұмңјлЎң к°„мЈјн• мҲҳ мһҲлӢӨ. мӮ¬л§үмқҙ м•„лӢҢ лҸҷл¬јмӣҗм—җ мһҲлҠ” лӮҷнғҖлҠ” мқёмӢқн•ҳм§Җ лӘ»н•ҳлҠ” м…ҲмқҙлӢӨ.
мқҙлІҲ кё°мҲ мқҖ '분нҸ¬ мҷё лҚ°мқҙн„°'лҘј нҷңмҡ©н•ҙ м Ғн•©н•ҳм§Җ м•ҠмқҖ нҠ№м„ұмқ„ м ңкұ°н•ҳлҠ” л°©мӢқмқҙлӢӨ.
лӮҷнғҖ нӣҲл Ём—җм„ңлҠ” м—¬мҡ° мӮ¬м§„мқҙ 분нҸ¬ мҷё лҚ°мқҙн„°к°Җ лҗңлӢӨ. м—¬мҡ° мӮ¬м§„м—җлҠ” нҳ№мқҙ м—Ҷм§Җл§Ң мӮ¬л§үмқҖ л°°кІҪмңјлЎң лӮҳмҳ¬ мҲҳ мһҲлӢӨ. 분нҸ¬ мҷё лҚ°мқҙн„°м—җм„ң 추м¶ңлҗң лӘЁл“ нҠ№м„ұмқ„ мҳҒ(0) лІЎн„°к°Җ лҸј мҶҢл©ён•ҳлҸ„лЎқ лӘЁлҚё н•ҷмҠө кіјм •мқ„ к·ңм ңн•ҳл©ҙ м Ғн•©н•ҳм§Җ м•ҠмқҖ нҠ№м„ұмқҙ м–өм ңлҗҗлӢӨ.
мқҙ л°©мӢқмқҖ кё°мЎҙмқҳ мқҙлҜём§Җ лҚ°мқҙн„° 분м„қ мөңмӢ л°©лІ•лЎ кіј 비көҗн–Ҳмқ„ л•Ң мқҙлҜём§Җ 분лҘҳ л¬ём ңм—җм„ң мөңлҢҖ 12%, к°қмІҙ кІҖм¶ң л¬ём ңм—җм„ң мөңлҢҖ 3%, к°қмІҙ м§Җм—ӯнҷ” л¬ём ңм—җм„ң мөңлҢҖ 8% мҳҲмёЎ м •нҷ•лҸ„к°Җ н–ҘмғҒлҗҗлӢӨ.
м ң1 м Җмһҗмқё л°•лҸҷлҜј л°•мӮ¬кіјм • н•ҷмғқмқҖ "분лҘҳ, нҡҢк·Җ 분м„қмқ„ 비лЎҜн•ң лӢӨм–‘н•ң кё°кі„ н•ҷмҠө л¬ём ңм—җ нҸӯл„“кІҢ м Ғмҡ©лҗ мҲҳ мһҲм–ҙ мӢ¬мёө н•ҷмҠөмқҳ м „л°ҳм Ғмқё м„ұлҠҘ к°ңм„ м—җ кё°м—¬н• мҲҳ мһҲлӢӨ"кі л§җн–ҲлӢӨ.
м—°кө¬нҢҖмқ„ м§ҖлҸ„н•ң мқҙмһ¬кёё көҗмҲҳлҸ„ "мқҙ кё°мҲ мқҙ н…җм„ңн”ҢлЎңмҡ° нҳ№мқҖ нҢҢмқҙнҶ м№ҳмҷҖ к°ҷмқҖ кё°мЎҙмқҳ мӢ¬мёө н•ҷмҠө лқјмқҙлёҢлҹ¬лҰ¬м—җ 추к°Җлҗҳл©ҙ кё°кі„ н•ҷмҠө л°Ҹ мӢ¬мёө н•ҷмҠө н•ҷкі„м—җ нҒ° нҢҢкёүнҡЁкіјлҘј лӮј мҲҳ мһҲмқ„ кІғ"мқҙлқјкі л§җн–ҲлӢӨ.